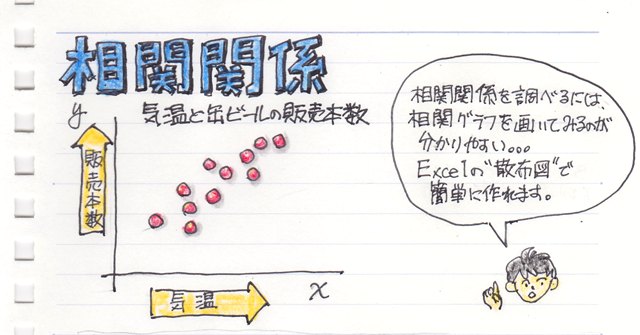
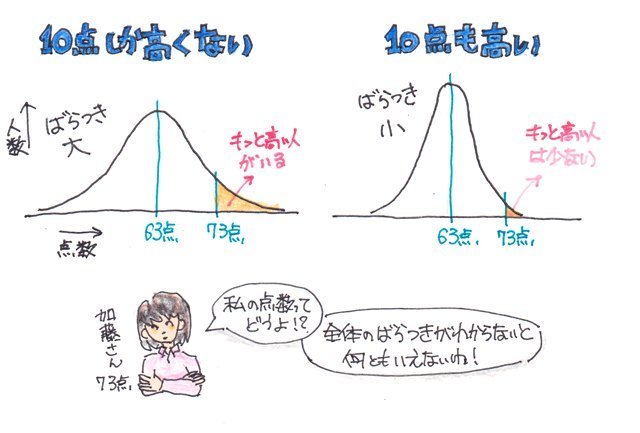
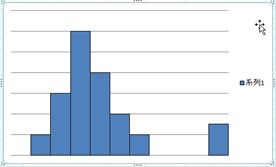
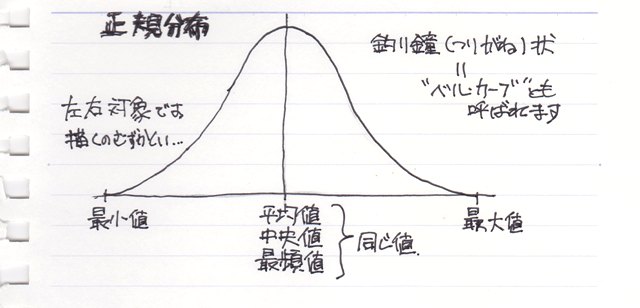
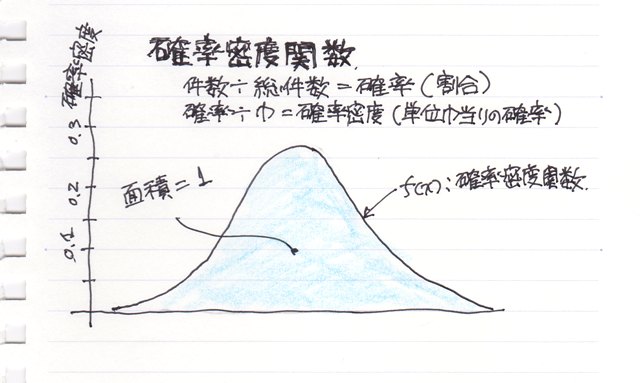
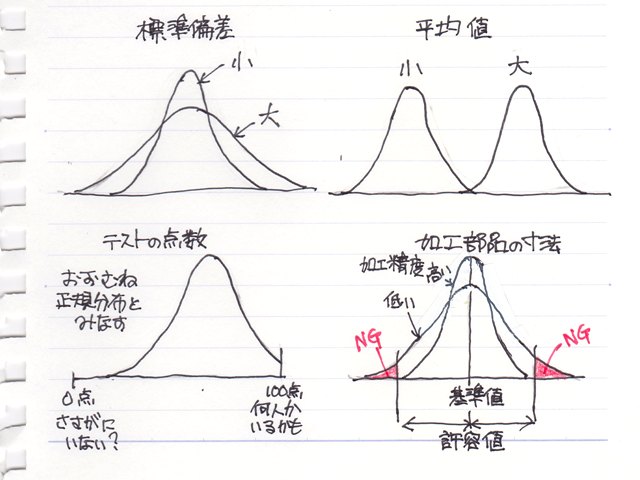
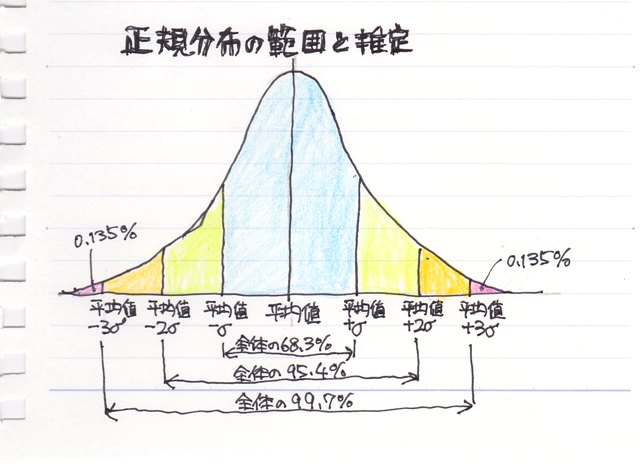
���փO���t�i�U�z�}�j�������Ɖ悢�Ċm�F���Ȃ��ƊԈႢ�������Ƃ��Ă��܂��P�[�X���������肵�܂��B
����͂���Ȃ��Ƃ��܂߂āA���֕��͂ŋC�����Ă����������Ƃ��܂Ƃ߂Ă݂܂����B
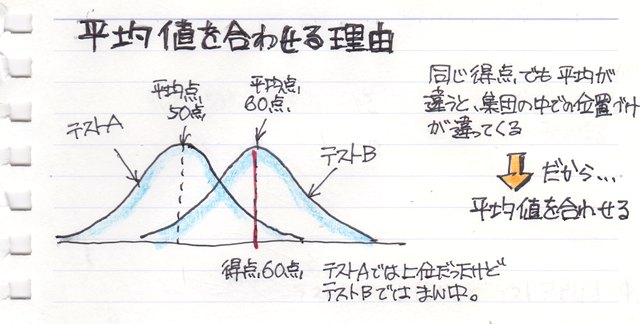
�O��l
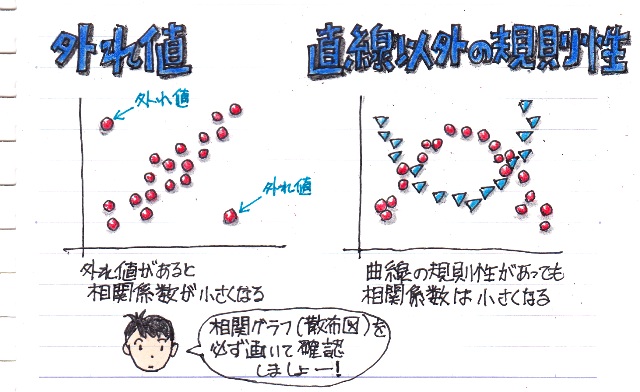
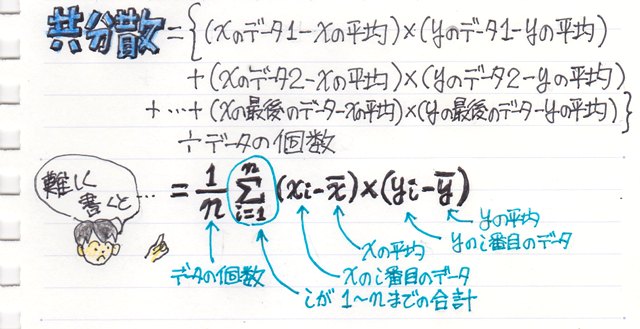
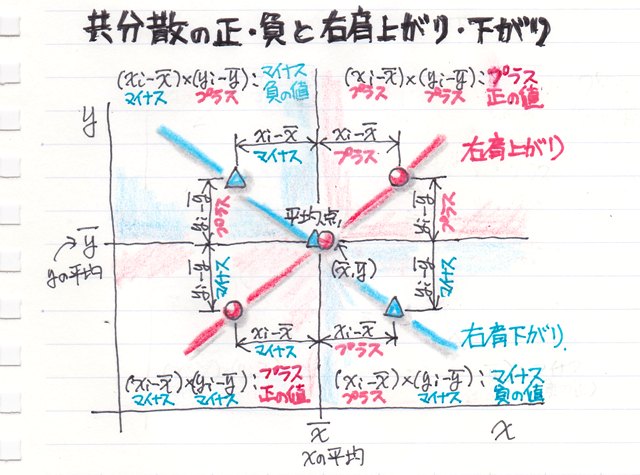
�g�O��l�h�Ƃ����̂́A�f�[�^�̓��̓~�X��������A�قȂ�f�[�^�����݂����肵�āA�ɒ[�ɑ傫���i�������j�f�[�^�̂��ƂŁA���̊O��l������Ɓg���ϒl�h���傫���ς���Ă��܂����Ƃ��悭�m���Ă��܂��B
���֕��͂ł��A�O��l������Ƒ��W�����������Ȃ��Ă��܂��܂��B
�������������ɂ͑��փO���t�i�U�z�}�j���悢�Ă݂Ȃ��ƌ��߂����Ă��܂��܂��B
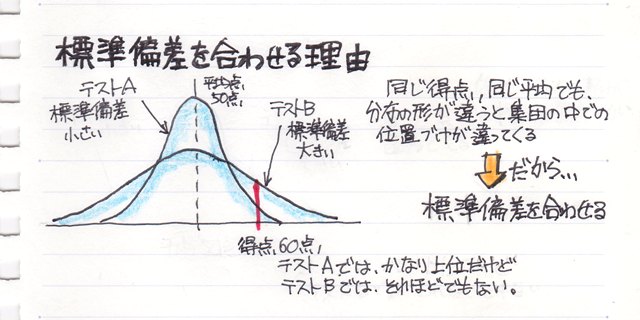
�����ȊO�̋K����
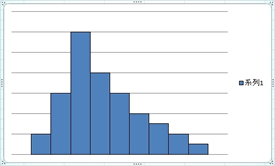
�O������������悤�ɁA���W���͕��z�������ɋߎ��ł���ꍇ�̑��ւ�\�����l�ł��B
�Ȃ̂ŁA��̐}�̂悤�ɋȐ��̋K���������Ă��A���W���ł͑��ւ������悤�Ȍ��ʂɂȂ��Ă��܂����Ƃ�����܂��B
�̂ŁA��������փO���t�i�U�z�}�j���悢�Ă݂邱�Ƃ��K�v�ł��B�B
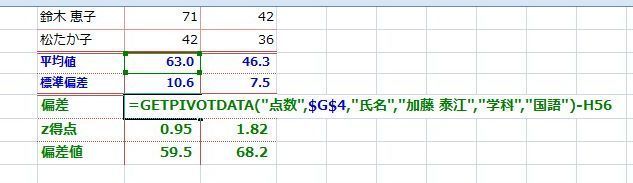
�f�[�^�̍��݁i�w�ʂɂ���j
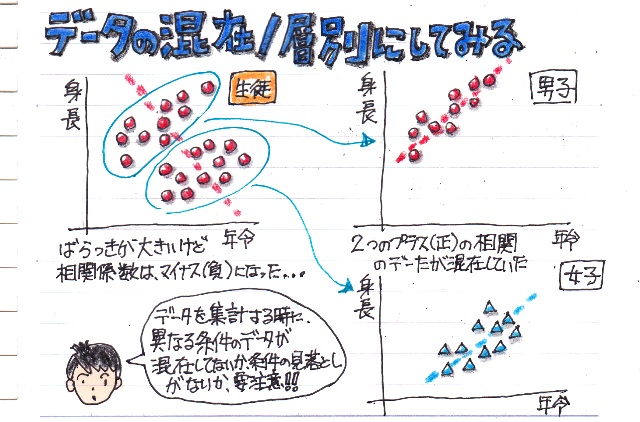
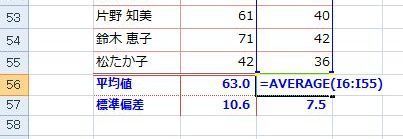
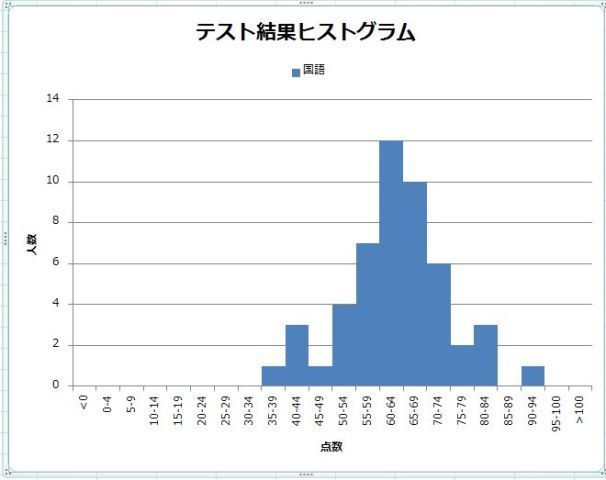
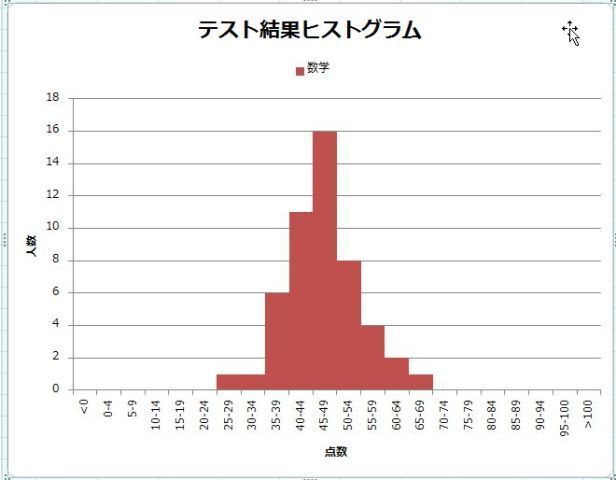
�����������փO���t�i�U�z�}�j���悢�Ă݂Ă��A���̃f�[�^�ɖ{���ʂȃf�[�^�Ƃ��Ĉ���Ȃ���Ȃ�Ȃ����̂Ȃ̂ɂ���ɋC�Â����Ɉꏏ�ɍ����Ă��܂��A���ւ������Ȃ��Ă��܂�����A��̐}�̗�̗l�ɁA�������t�̌��ʂɂȂ��Ă��܂����Ƃ�����܂��B
�ΏۂƂ���f�[�^�ɈقȂ�������B��Ă��Ȃ����A�悭�ᖡ���Ȃ���Ȃ�܂���B
����́A���̃f�[�^�Ɋւ�����I�Ȓm�����K�v�ɂȂ�ꍇ�������āA���Ƒ�ςł��B�B�B
�I������
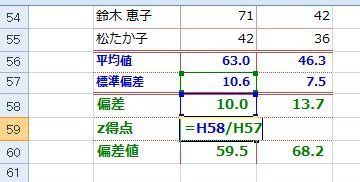
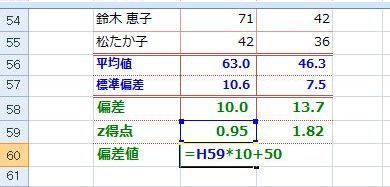
�L���͈͂ɕ��z����S�̂̃f�[�^�͖��炩�ɑ��ւ�������ǁA���̒���1���������o���ƁA���ւ��������Ȃ��Ă��܂����Ƃ��g�I�����ʁh�ƌĂ�܂��B
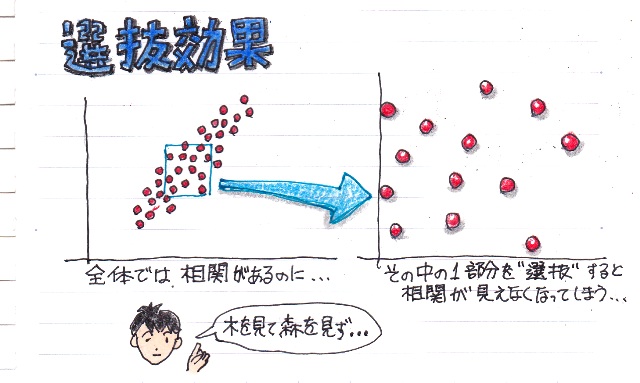
���̑I�����ʂł悭�Ⴆ�ɋ�������̂��A�������s���č��i�҂́A�����̎��̓��_�ƁA���w��̐��т̑��ւ��݂�Ƒ��ւ������Ƃ������ʂɂȂ�Ƃ����b�B�B�B
���̏ꍇ�A�g�����ō��i�����h�Ŕ͈͂������I�����Ă��܂������Ƃ����ւ����Ă��܂������ɂȂ�킯�ł��B�B�B
�Ȃ̂����ǁA�I�����ꂽ�͈͂ő��ւ��キ�Ȃ�̂́A�����ĕ��͂��Ԉ���Ă���킯�ł͂Ȃ�����͂���Ő^���Ȗ�ł��B
�܂�A���ۂɕK�v�Ƃ��镪�͈͂̔͂��ǂ����ɂ���āA���ւ͕ς��܂��B
�����A�S�̂���I�������͈͂̑��ւ����߂������́A�S�̂̑��ւ����߂������ŁA�I�������͈͂̑��ւ�]������ׂ����Ǝv���܂��B�B
���ƁA������ŁA���W�������ł͕�����Ȃ��Ƃ���A���߂����Ă��܂��Ƃ��낪����܂��B
�U�z�}���悯�����Ȃ���Ƃ���A�U�z�}���悢�Ă�������Ȃ����Ƃ�����܂��B
�f�[�^�̔w�i���悭���āi�f�[�^�����W���āA���͂��āj�������i�Ó��ȁj���ւ������܂��傤�I�I
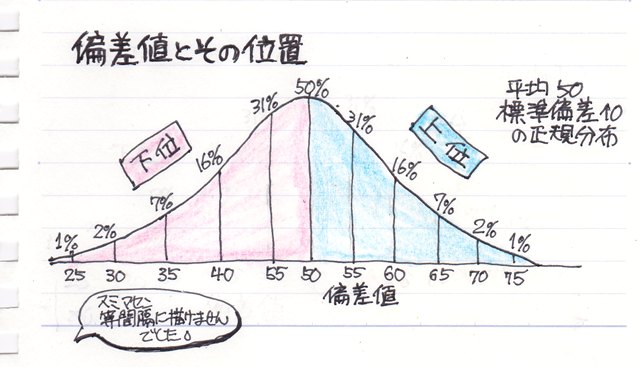
���Ď��́A���̎U�z�}�ɂ��ĊȒP�ɂ܂Ƃ߂Ă݂܂����B
�\����
�o�b�N�i���o�[
����1 ���֊W�ɂ��Ă܂Ƃ߂Ă݂�
�֘A�y�[�W
����3 �U�z�}�ɂ��Ă܂Ƃ߂Ă݂��i�ǂ����������H�j
����4.1 �U�z�}���悢�Ă݂� / �O���t
COVAR���ŋ����U�����߂Ă݂�
CORREL���ő��W�������߂Ă݂��h
�f�[�^���͂̉��/���j���[














![�y�y�V�u�b�N�X�Ȃ炢�ł����������z���v�w���ŋ��̊w��ł��� [ �����[ ]](https://hbb.afl.rakuten.co.jp/hgb/?pc=http%3a%2f%2fthumbnail.image.rakuten.co.jp%2f%400_mall%2fbook%2fcabinet%2f2214%2f9784478022214.jpg%3f_ex%3d300x300&m=http%3a%2f%2fthumbnail.image.rakuten.co.jp%2f%400_mall%2fbook%2fcabinet%2f2214%2f9784478022214.jpg%3f_ex%3d80x80)